![]()
Using Unicode on the web
for polytonic Greek, and Syriac
![]()
When I had to put some ancient Greek in my website, I used to use the old Scholars Press spionic font, where a was alpha, and so on. I provided a link where the font was available, and just specified <FONT FACE=SpIonic>...</FONT> around the bits in Greek. Other people used other fonts, and each font had a different way to represent alpha-with-a-rough-breathing, final sigma, and the like. In Spionic final sigma was 'j'; it was different if you used the Windows symbol font (as many did). But this is all passing away, with the advent of unicode.
In Unicode, final sigma is always the same letter or code, whoever wrote the font. This, frankly, is a relief, and should make it easier to write web pages.
But unicode is a bit of a mystery to programmers and website authors, unless they have already grappled with it! The resources on the web are frankly rather difficult to grasp! The purpose of this page is to explain how to do it.
Note that I am relying on you having some unicode fonts installed! If you have not, get the free Titus Cyberbit Basic truetype font. In fact you should get this anyway, because it is one of the few unicode fonts that implements all the characters: most of them only implement a few.
Here's some practical notes on how to do it. These are all oriented towards someone running Windows XP, I should add, which comes with the free unicode font Palatino Linotype.
The best way to handle unicode on your webpages is to treat it like a font, which you have to specify. Use CSS, and define a style, and then stick that around the text that you want to use.
So for the Greek above, I define this style at the top of each webpage, between the <HEAD>...</HEAD> tags:
.Greek { font-family : "Gentium, Palatino Linotype, Titus Cyberbit Basic, Aisa Unicode, Arial Unicode MS, Cardo, Microsoft Sans Serif"; } </style><style>
And then I stick a tag <SPAN Class=Greek>....</SPAN> around the text that I want to be displayed in whichever of those fonts the user has.
Now here's some unicode polytonic Greek: Εν ἀρχῇ ἦν ὁ λόγος, καὶ ὁ λόγος ἦν πρὸς τὸν θεόν, καὶ θεὸς ἦν ὁ λόγος. This was done as above, and, so long as you have one of those fonts, it should display just fine! How was it done? Each character on the webpage is a HTML symbol code. The first one (Ε) is Ε the third character (ἀ) is ἀ and so on. You can enter any character on a web page using its unicode hex value, surrounded by &#x....; and it will work.
How do I find the unicode hex value for the symbol I want? Well, there are tables of these things in PDF form, available from http://www.unicode.org/charts/. The one for ancient Greek is http://www.unicode.org/charts/PDF/U0370.pdf. If you look at this, you get a strange table. What matters are the numerals under each symbol. So beta (β) has 03B2 under it. Here's a snippet from that pdf:
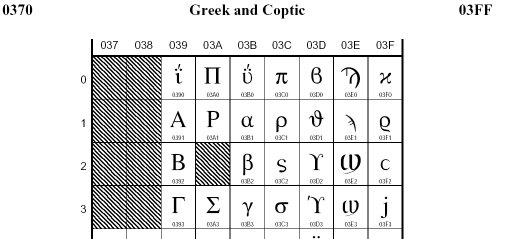
That means that the HTML code for a beta symbol is β and if you enter that, you will get a beta.
The other way to find a character is to open up charmap (Start|Run|charmap and enter) in Windows XP, change the font to your unicode font (Titus cyberbit basic -- if you did not get this, do so NOW). Then you can browse the characters available in that font, and you will see that beta is there -- you have to scroll down a bit in the symbols in the font to find it -- and on the bottom of the form is that same hex code, 03B2:
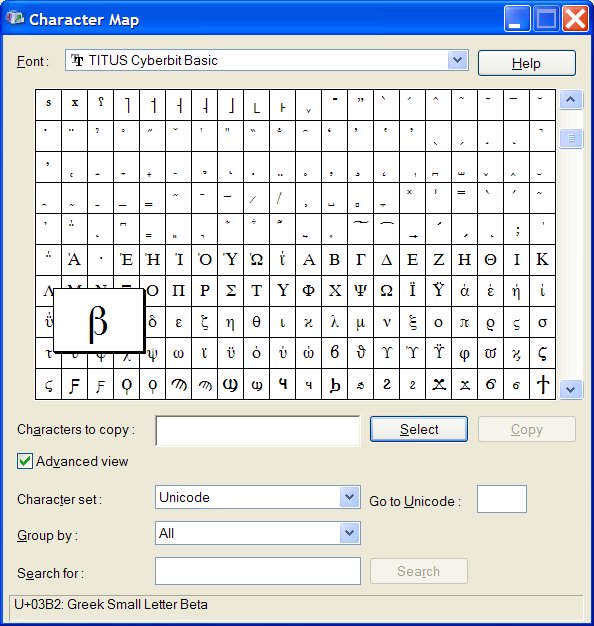
1. Your main problem with all this is the one we have always had with webpages -- what if the user doesn't have the font? You need to supply in your code a reasonable number of common fonts, and provide a link to where they can get a free one.
You may also find that the symbol in one font is not the same as in another. This happens when a character can be drawn in different ways. Thus the Syriac fonts all use the same character for ALAP, but how this was drawn changed down the centuries. Some fonts (e.g. Estrangelo Edessa, which comes with XP) show ALAP in the ancient Estrangelo script. Titus Cyberbit basic shows a very different looking ALAP, in the modern Serto script. This is correct, and normal; and you must ensure that your CSS displays what you want it to!
You will see references online to 'setting the page type to UTF-8'. Now you can do this; but all it strictly means is that your ordinary ASCII text is in unicode, and so takes up 16 bits per character rather than 8 1. That makes it twice as slow to download, so I don't see why you want to do this. It isn't necessary for using unicode for special characters.
You will also see references to setting your browser to use a unicode font, etc. This works fine until the first page that resets it to something else, and leaves it there.
Neither of these two approaches should be taken. They are unnecessary distractions. Ignore them.
2. There is a second problem. Unicode is HUGE. That means a unicode font that implemented all the characters is HUGE also. Titus Cyberbit Basic does implement them, which makes it a really useful font to have around, and to use as a backstop in your web pages. (That's why I told you to use it...).
The upshot of this is that, just because a font is a 'unicode' font, it doesn't mean that it will have the characters you want. All it means is that the symbol at hex offset 03B2 will always be beta; not that the font creator drew a beta and put it in that slot.
If you use charmap and look at the XP supplied Palatino Linotype font, you will find that it has Greek polytonic characters, but no Syriac; if you look at the XP supplied Estrangelo Edessa font, you will find that it has Syriac, but only a few Greek characters, none of them polytonic.
3. The third problem is; how on earth do you enter these characters in your webpages? I must confess that, as a programmer, I cheat. I have a macro! I just type in my Greek text in the old SpIonic format (log&oj = λογ́ος), highlight the text, hit a button and it goes through it and converts it to the HTML symbols. The macro is basically a huge 'if-else', for all the Greek characters, and combinations of accents, that are shown in the PDF chart above. The business of combining accents, breathings and iota subscripts is what makes it tedious to write, but straightforward enough. (I haven't made one for Syriac yet, hence the lack of Syriac on this page!).
4. You may find that your HTML editor is not good on recognising some unicode symbols. I am typing this in Frontpage 2000, which is happy about polytonic Greek so long as I specify the style in the page header, and not in an external .css file. It isn't happy about Syriac however I do it! Dreamweaver is better on this, I find, as is Frontpage 2002.
1. I have left this statement for clarity for those who don't really care about the details, but it is not quite accurate. Strictly speaking, you only get 16-bits for every character if the page is set to UTF-16. UTF-8 has an optimisation, whereby the first 256 characters are rendered in 8 bits, for compatability with ASCII. The remainder are held in 16-bit. So UTF-8 is in fact a variable-length encoding, so setting the page type to UTF-8 if the page only contains plain ASCII text makes it no larger than any other 8-bit encoding. See http://en.wikipedia.org/wiki/UTF-8 for more details.
In terms of efficiency, each Greek character entered using the HTML entity reference syntax (e.g. Ε) takes 8 ASCII characters (=a total of 64 bits or 8 bytes), to represent it. So this is actually bulkier than an HTML page which actually contains UTF-8 characters. However the latter is very hard to understand and edit, and is not properly supported by browsers. While we really live in an ASCII world, your pages will work much better with HTML entity reference syntax. (Many thanks to Jim Malone for this correction).
![]()
Constructive feedback is welcomed to Roger Pearse.
Written 31st March 2006.
Updated 20th July 2006.
![]()
This page has been online since 31st March 2006.
![]()
Return to Roger Pearse's Pages